As more artificial intelligence applications move to smartphones, deep learning models are getting smaller to allow apps to run faster and save battery power.
As more artificial intelligence applications move to smartphones, deep learning models are getting smaller to allow apps to run faster and save battery power. Now, MIT researchers have a new and better way to compress models.
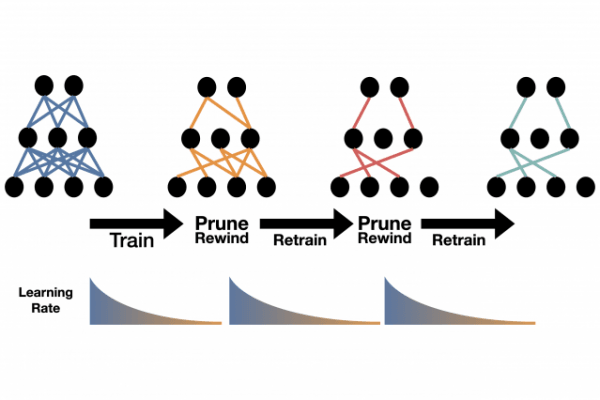
It’s so simple that they unveiled it in a tweet last month: Train the model, prune its weakest connections, retrain the model at its fast, early training rate, and repeat, until the model is as tiny as you want.
“That’s it,” says Alex Renda, a PhD student at MIT. “The standard things people do to prune their models are crazy complicated.”
Renda discussed the technique when the International Conference of Learning Representations (ICLR) convened remotely this month. Renda is a co-author of the work with Jonathan Frankle, a fellow PhD student in MIT’s Department of Electrical Engineering and Computer Science (EECS), and Michael Carbin, an assistant professor of electrical engineering and computer science — all members of the Computer Science and Artificial Science Laboratory.
Read more at Massachusetts Institute of Technology
Image: MIT researchers have proposed a technique for shrinking deep learning models that they say is simpler and produces more accurate results than state-of-the-art methods. It works by retraining the smaller, pruned model at its faster, initial learning rate. CREDIT: Alex Renda